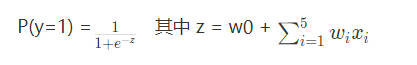defparse_num(s): if s isNone: returnNone s = s.strip() ifnot s or s.lower() == "nan": returnNone try: returnfloat(s) except: returnNone
defparse_label(s): try: v = int(s) if v in (0, 1): return v returnNone except: returnNone
defis_valid_value(idx, v): if v isNone: returnFalse if idx in (0, 1): # writes / reads return v >= 0 if idx in (2, 3): # avg_write_ms / avg_read_ms return0 <= v <= 1000 if idx == 4: # years return0 <= v <= 20 returnFalse
defclean_row(feats, means, medians): x = [] for i, v inenumerate(feats): if v isNone: x.append(means[i]) else: if is_valid_value(i, v): x.append(v) else: x.append(medians[i]) return x
defsigmoid(z): if z >= 0: ez = math.exp(-z) return1.0 / (1.0 + ez) else: ez = math.exp(z) return ez / (1.0 + ez)
# ---------------- 主程序 ---------------- N = int(input().strip()) train_rows = [input().strip().split(",") for _ inrange(N)]
M = int(input().strip()) test_rows = [input().strip().split(",") for _ inrange(M)]
# 统计训练集有效值 valid_values = [[] for _ inrange(5)] train_data = [] for row in train_rows: iflen(row) < 7: continue feats = [parse_num(row[1]), parse_num(row[2]), parse_num(row[3]), parse_num(row[4]), parse_num(row[5])] y = parse_label(row[6]) if y isNone: continue for i, v inenumerate(feats): if is_valid_value(i, v): valid_values[i].append(v) train_data.append((feats, y))
means, medians = [], [] for i inrange(5): if valid_values[i]: means.append(mean(valid_values[i])) medians.append(median(valid_values[i])) else: means.append(0.0) medians.append(0.0)
# 清洗训练数据 X, Y = [], [] for feats, y in train_data: X.append(clean_row(feats, means, medians)) Y.append(float(y))
# 初始化参数 n_train = len(X) d = 5 w = [0.0] * d b = 0.0 lr = 0.01 epochs = 100
# 批量梯度下降 if n_train > 0: for _ inrange(epochs): grad_w = [0.0] * d grad_b = 0.0 for xi, yi inzip(X, Y): z = b + sum(w[j] * xi[j] for j inrange(d)) pi = sigmoid(z) diff = (pi - yi) for j inrange(d): grad_w[j] += diff * xi[j] grad_b += diff invN = 1.0 / n_train for j inrange(d): w[j] -= lr * (grad_w[j] * invN) b -= lr * (grad_b * invN)
# 预测 for row in test_rows: feats = [None] * 5 iflen(row) >= 6: feats = [parse_num(row[1]), parse_num(row[2]), parse_num(row[3]), parse_num(row[4]), parse_num(row[5])] x = clean_row(feats, means, medians) z = b + sum(w[j] * x[j] for j inrange(d)) p = sigmoid(z) print(1if p >= 0.5else0)